Stop Wasting Your Claude Usage Limits: 6 Hacks to Get 10x More From Every Chat

Hey future-proof friends 💜
So I posted an IG Reel on Friday sharing tips to help avoid hitting Claude usage limits…
Nothing fancy… I thought it’d get maybe 1000 views…
It hit over 1.2 million views in 48 hours!! 🤯

Turns out running out of Claude usage mid-task is a universal frustration that’s annoying a lot of people.
Especially if you’re on the Free or Pro plan and trying to build amazing things.
So today I’m breaking down how to squeeze every last drop of value out of your Claude usage, no matter which plan you’re on.
Chats Get More Token-Hungry As They Go
First very important thing you need to understand about Claude:
it doesn’t count messages like ChatGPT does - it counts tokens.
That means every word in, every word out and your entire chat history stacked on top.
And depending on how you use it, one conversation can burn through 10x more than another.
Claude re-reads your entire conversation history every time you send a message. The whole thing back from message one.
So if your first message is around 200 tokens, by message 30, that same type of question could cost thousands of tokens.
You could ask “can you tweak that last paragraph?“ and it costs 250x more than your opening message.
The question isn’t harder - your conversation just got heavier to process.
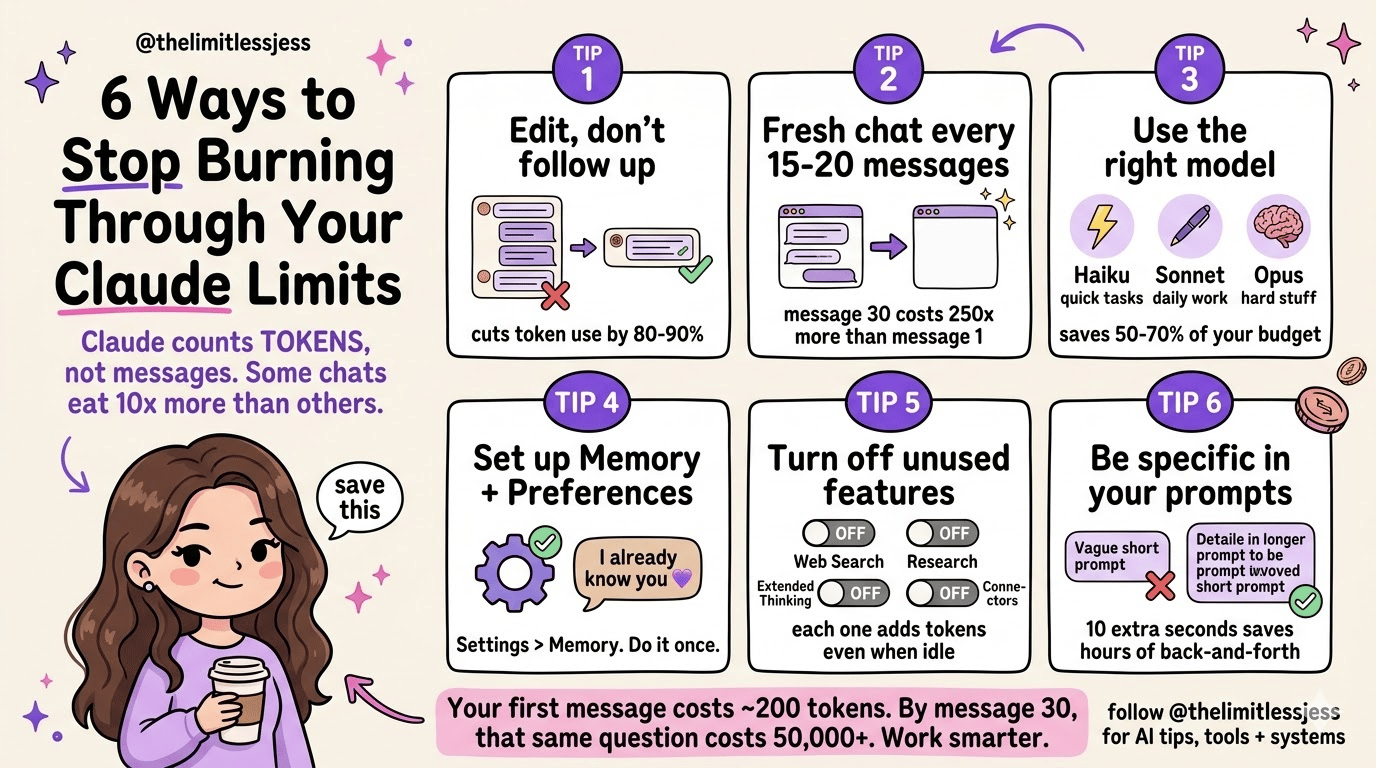
With that in mind - let’s dive into our 6 tips:
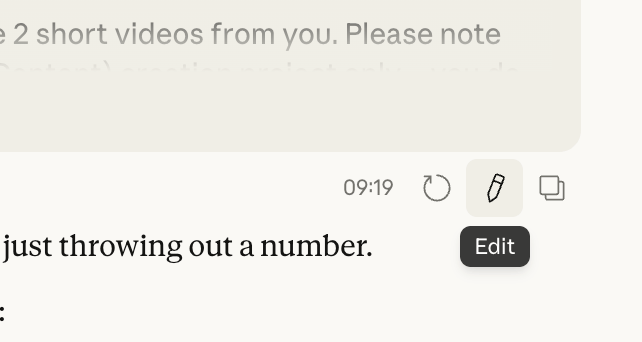
1. Edit your prompt, don’t send a follow-up
When Claude misses the mark, your instinct is to send a correction. But every follow-up adds to the stack, and Claude re-reads all of it again, including the bad response you didn’t want.
Instead: click edit on your original message and regenerate. The old response gets replaced, not added. Over 10 rounds, this alone can cut token usage by 80-90%.
2. Start fresh every 15-20 messages
After about 15-20 messages, copy Claude’s latest summary or output, open a new chat and paste it in.
That means you get a fresh token slate.
And Claude often performs better too because it’s not juggling 30 messages of context.
That “quick review” in a long thread can cost 50-100x what it would in a fresh chat.
Try this prompt:
I need to move this conversation to a fresh chat to save tokens.
Please compress everything we've covered into a briefing I can
paste into a new conversation. Include:
- The task we're working on (in one sentence)
- Key decisions we've made so far
- My preferences you've picked up (tone, style, format, anything specific)
- Current status (what's done, what's still left)
- Any outputs or text I need to carry forward
Keep it under 300 words. Format it so I can paste it straight
into a new chat and you'll have full context immediately.3. Use the right model (this is a BIG one)
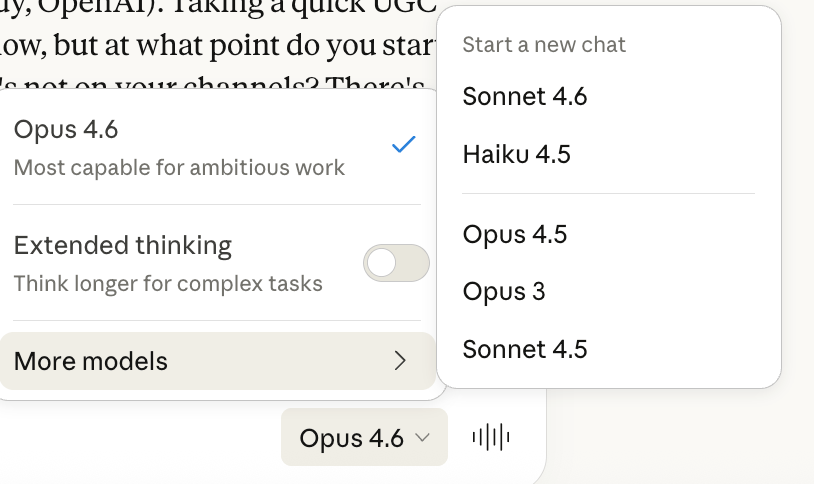
Most people use whichever model is selected by default.
But switching models strategically is probably the single highest-impact change you can make:
Haiku: Great for quick answers, brainstorming, grammar, reformatting. Although it’s not going to provide fully fleshed out responses - it’s fast and barely touches your usage.
Sonnet: Ideal for content writing, analysis, coding, day-to-day work. Smart enough for serious tasks without being token-hungry.
Opus: Now the big gun for deep research, complex logic, hard problems. It’s brilliant but expensive, so save it for when you genuinely need it.
Even though I’m on the Max plan, I still try to switch between all 3 - thinking about speed of response and cost.
There’s no reason to use Opus for a grammar check when Haiku does it in two seconds for a fraction of the cost.
Save the heavy hitter for the heavy work and that one habit alone could free up 50-70% of your budget.
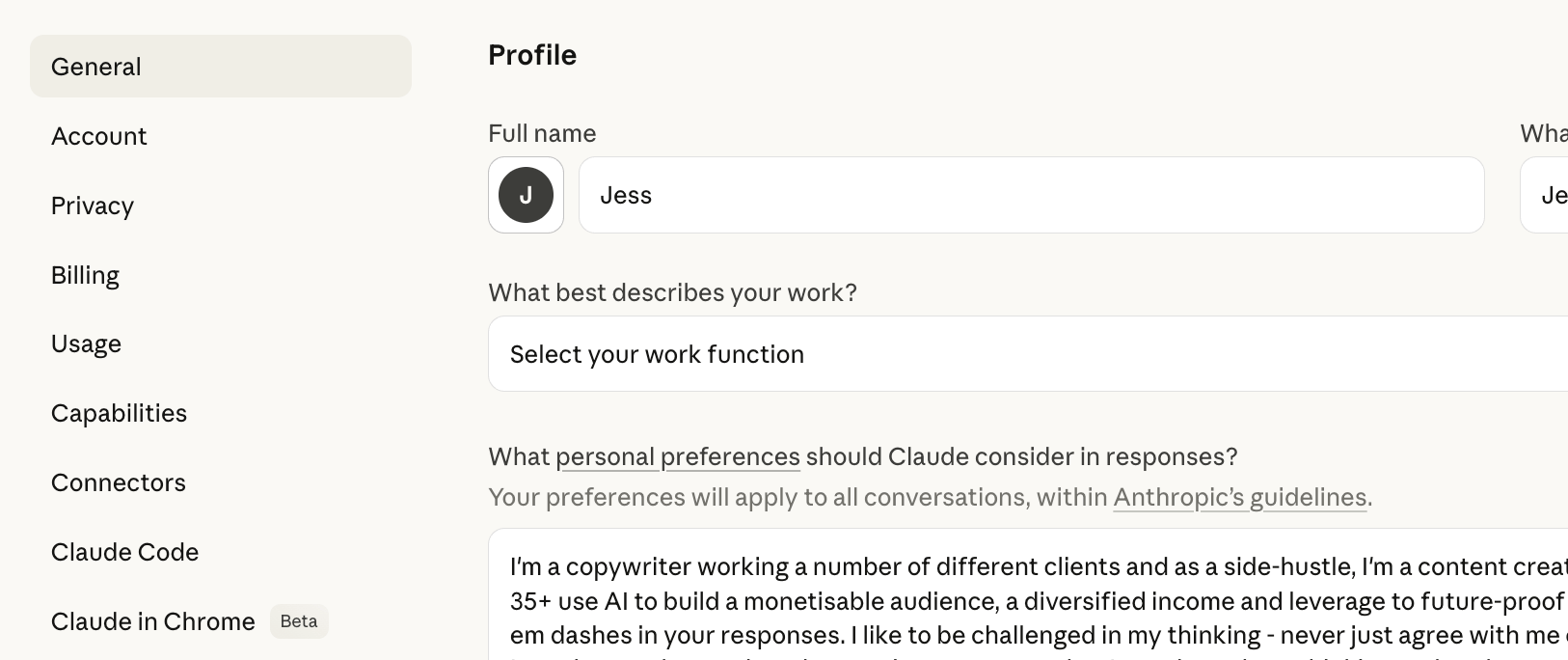
4. Set up Memory and Preferences
Without these, you can waste 3-5 messages every new chat just re-explaining who you are, what you do, what tone you want. That’s tokens gone before you’ve even started.
Go to Settings > General > Personal Preferences and store your basics once. Your role, your business, your writing style. Claude carries it into every chat automatically.
I have mine set up with my copywriting background, my preferred style, even the things I don’t want Claude to do (like using em dashes or agreeing with everything I say). Set it up once, save tokens forever.
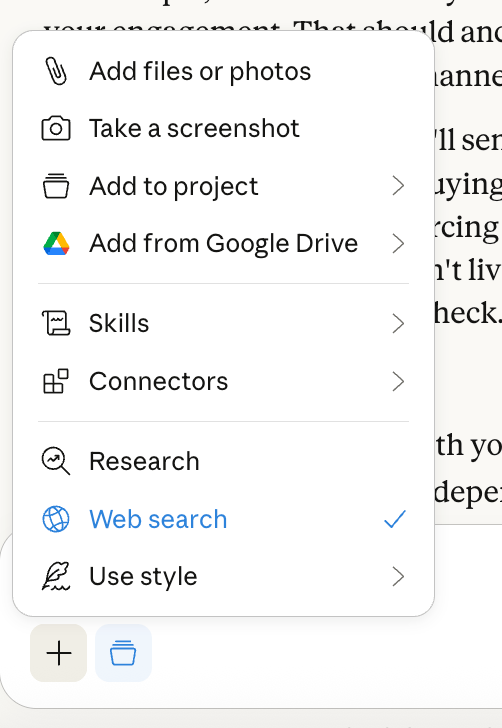
5. Turn off features you’re not using
Web search, research mode, connectors, and extended thinking are valuable features for the appropriate tasks, but they all add tokens to every response, even when you don’t need them.
Leave everything off by default and only switch things on when a task needs them.
6. Be specific in your prompts
Vague requests burn tokens (and also give you 💩results).The more specific you are upfront, the less back-and-forth you need.
Instead of “help me write a social media caption about AI”
Try “write a 150-word Instagram caption about how I used Claude to plan my content calendar this week, conversational tone, aimed at women 35+ building a side hustle.”
Ten extra seconds writing a better prompt saves you multiple rounds of corrections. Your 3pm self will thank you.
Save this handy cheatsheet (and share it with a fellow Claude lover)👇
Finally, I made something to help you set up & use Claude like a Pro
It’s called The Ultimate Claude Toolkit and it walks you through setting up Claude like a pro, all the settings most people never think to configure, plus a lot of essential basic Claude knowledge to help you master this incredible tool.
It’s a checklist in Notion so you can duplicate it into your own Notion workspace and work through it in a few minutes:
👉 Grab The Ultimate Claude Toolkit here
I’m still trying to get a hang of this Substack thing, so if you made it all the way down here, do let me know if you enjoyed this post 💜